SDD 实践:如何解决 Agent 记忆的上下文腐化与压缩丢失?
探讨在 Spec-Driven Development 中,如何通过 MemoryLint 扩展的边界治理与上下文接力,解决长对话中大模型记忆压缩导致的上下文丢失问题。
系列阅读:本文是 SDD (Spec-Driven Development) 系列的延伸探讨。建议先回顾 《SDD Series Part 3: Future》 了解“意图基础设施”的背景概念。
TL;DR
- 痛点:长周期 AI 辅助开发中,LLM 记忆文件臃肿会导致严重的“上下文丢失 (Context Loss)”。
- 方案:
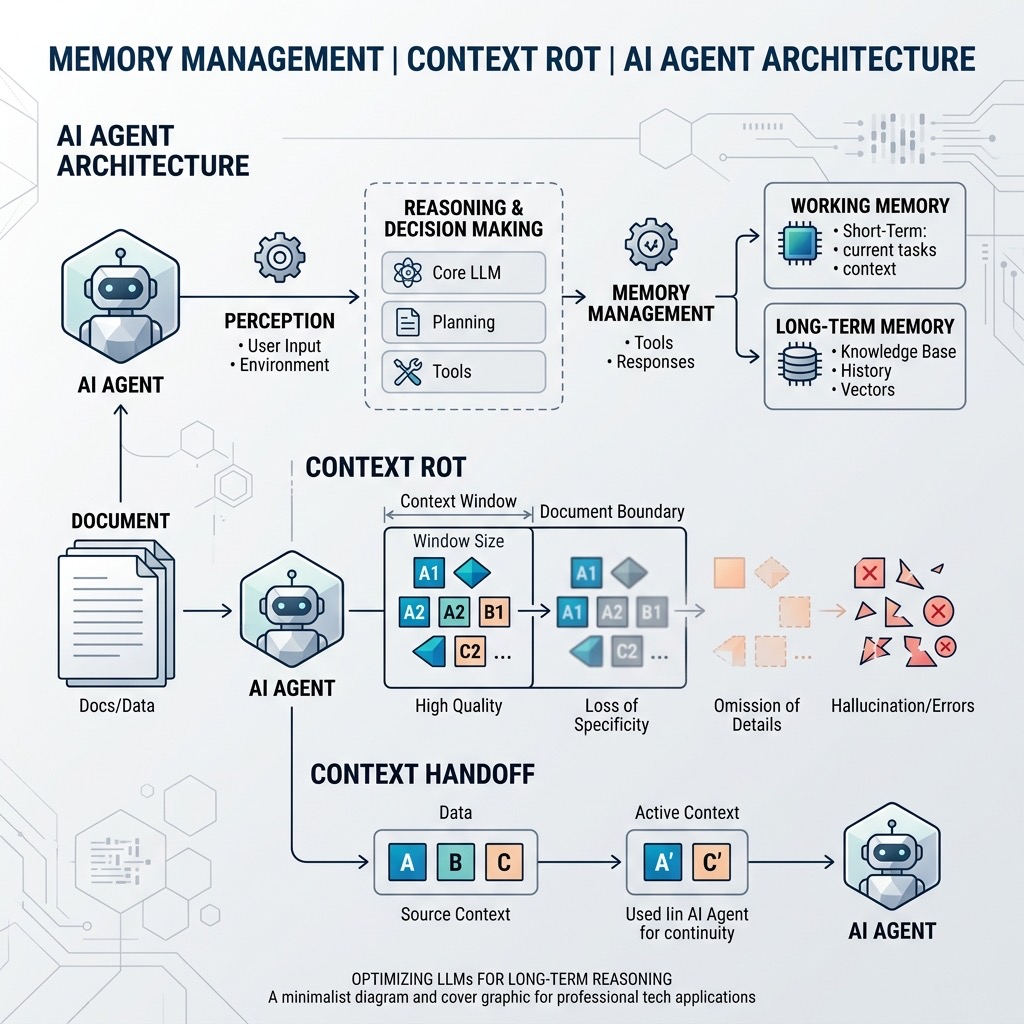
memorylint扩展通过物理隔离、上下文流式接力和强制即时唤醒,从架构层面遏制“上下文腐化 (Context Rot)”。- 核心结论:解决大模型记忆衰退,不能单纯依赖扩展 Context Window,更需要构建高内聚、低耦合的文档工程架构。
在之前的文章 《SDD Series Part 3: Future》 中,我们讨论了意图基础设施(Intent Infrastructure)和上下文腐化(Context Rot)的概念。文章发布后,有朋友提出了一个非常敏锐且切中要害的问题:
“I read your Spec-Driven Development Part 3 post on intent infrastructure and context rot. I’m curious how are you dealing with context loss from compaction?” (我阅读了你的 SDD Part 3 关于意图基础设施和上下文腐化的文章。我很好奇,你是如何处理因上下文压缩而导致的记忆丢失问题的?)
在 AI 辅助编程的长对话中,这几乎是所有开发者都会遇到的痛点。当项目规范、架构原则和基础设施命令越来越多时,LLM 在处理超长上下文时极易产生注意力衰减,或者在不断“压缩/总结”记忆的过程中丢失关键细节。
今天,我们就来深入探讨在 SDD 规范下,专门为 GitHub Spec Kit 工作流 打造的 memorylint 扩展,是如何从系统工程层面解决这一痛点的。
记忆崩塌的根源:职责不清与文件膨胀
在 SDD 流程中,Agent 通常依赖两个核心的长期记忆文件:
AGENTS.md:负责基础设施 (Infrastructure),如构建命令、测试规范、Git 工作流。.specify/memory/constitution.md:负责项目架构 (Architecture),如 MVC 模式、状态管理、业务约束。
在实际开发中,开发者或 AI 经常会“偷懒”,把本该属于业务架构的约束,随手写进了全局的 AGENTS.md。久而久之,AGENTS.md 变成了一个无所不包的垃圾桶。
当记忆文件变得过于臃肿(Token 密度极高)时,LLM 就被迫在极长的上下文中寻找核心规则,这必然导致上下文丢失 (Context loss from compaction)。单纯增加 LLM 的 Context Window 并不能解决问题,反而会引入更多的“注意力噪音”。
MemoryLint:架构守门员
memorylint 并没有试图去优化大模型的压缩算法,而是通过一套高内聚低耦合的文档工程架构,从源头上遏制 Context Rot。它主要依赖以下四大机制:
1. 边界治理:物理隔离,降低 Token 密度 (Boundary Auditing)
要解决压缩丢失,第一步就是不要让文件大到需要被强力压缩的程度。
memorylint 扮演了一个“架构守门员”的角色。它通过挂载 before_constitution 生命周期 hook,定期对 AGENTS.md 进行审计:
- 识别并修剪 (Prune):敏锐地发现并提取出那些误入
AGENTS.md的架构层规则(例如“必须使用 Zustand 管理状态”)。 - 边界归位:确保
AGENTS.md永远保持纯粹,仅包含测试、构建等基础设施相关的严格指令。
通过物理隔离,极大地降低了单个记忆文件的阅读负担。
2. 上下文接力:安全无损的记忆转移 (Context Handoff)
当 memorylint 把架构规则从 AGENTS.md 中提取出来后,如何把它们安全地放进 constitution.md 呢?如果用脚本直接进行硬编码替换,极易造成原有内容的覆盖和丢失。
这里的巧妙之处在于它的 Output Protocol。
memorylint 不会直接去覆写 constitution.md,而是将提取出的规则以 Markdown 列表的形式,打印到当前的对话历史(Short-term LLM Memory)中:
1
2
3
### Extracted Architectural Rules for Constitution
- Rule: Ensure all state management follows the Zustand store pattern.
- Rule: Extract domain logic from UI components.
随后,执行 /speckit.constitution 命令时,系统会读取当前会话中的这段短期上下文,并由 LLM 将其与旧的 Constitution 进行语义融合。这种基于对话流的上下文接力避免了脚本直接覆盖 Constitution 的风险,但仍需要通过 diff 与 review 验证合并结果。
3. 强制即时唤醒:打破历史遗忘曲线 (Mandatory Active Loading)
在动辄几十轮的长对话中,即使规则写得再清晰,也极易被 LLM 的滑动窗口(Sliding Window)“压”出短期记忆区。
为了解决这一问题,memorylint 引入了一个强制的门控钩子:load-agents.md。 它挂载在 before_plan hook 上,这意味着:在 Agent 开始制定任何开发规划(生成 plan.md)之前,必须先执行一次强制读取操作,将 AGENTS.md 的原文完整加载到当前的活跃上下文 (Active Context) 中。
如果文件不存在或读取失败,流程会直接报错熔断。这种“强制即时唤醒”机制,确保了在最关键的规划阶段,Agent 所依赖的永远是最新、最全的基准规则,从而直接免疫了长对话历史造成的压缩遗忘。
4. 自动化富化:对齐工程现状 (Infrastructure Enrichment)
最后,Context Rot 还有一种表现形式:文档与代码工程的实际情况脱节。 为了防止 Agent 因为初始上下文不足而产生幻觉,memorylint 在审计时,会顺便扫描工作区(如 package.json, Makefile 等),如果发现缺失了核心的基础设施说明(比如漏写了 npm run test 的规范),它会自动推断并补充到 AGENTS.md 中。
结语
在构建 Agentic Workflow 时,解决 Context Loss 不能仅仅指望模型基础能力的“力大砖飞”(如无限制扩大 Context Window)。
memorylint 给我们的核心启示在于:好的意图基础设施,应当像优秀的软件架构一样,具备清晰的职责边界(Separation of Concerns)、可靠的上下文流转(Context Handoff)以及确定性的运行时门控(Mandatory Gates)。
通过治理好这些记忆文件,我们才能在长周期的 SDD 开发中,真正保持 AI 行为的稳定与可控。